Feature Introduction & Feature Comparison
Lifetime Membership
Comparison of Daza Matrix vs. Large Language Models in Formula Design
| Daza Matrix | Large Language Models (LLMs) (including ChatGPT, Gemini, Claude, DeepSeek, Doubao, etc.) | |
|---|---|---|
| Hallucination Generation During Literature Analysis |
No Hallucinations
Compared with LLMs, the CNN+NLP+Domain-Specific NLP solution can better understand and process professional terminology and domain knowledge, reducing misunderstandings caused by general-purpose models. Meanwhile, it is more modular, facilitating adjustments and optimizations for specific tasks to reduce hallucinations; it also has better interpretability, enabling more effective tracking of the model's decision-making process, thus making it easier to detect and correct hallucination issues. For highly domain-specific literature analysis with high requirements for accuracy and controllability, the CNN+NLP+Domain-Specific NLP solution is a better choice. |
Hallucinations Occur
LLMs have extensive and heterogeneous data sources with varying data quality. The models learn and reflect these flaws and errors, leading to the generation of untrue or misleading content. LLMs generate text based on probabilities, tending to select high-probability vocabulary combinations rather than basing output on facts or logic. This mechanism may result in content that is statistically reasonable but inconsistent with facts. For example, when you ask an LLM to analyze 100 pieces of literature, identify all species and supplement names mentioned, and sort them by word frequency, the results it provides will include some species and supplements that do not exist in the literature at all, while many important species and supplements present in the literature are omitted—and the results vary with each generation. |
| Range of Supplements Recommended for Diseases and Demands |
Over 2 million species worldwide + over 100,000 supplements worldwide
FoodWake's curated Global Supplement Library has now included more than 100,000 supplements, making it the world's largest supplement database. |
Theoretically up to several thousand types. However, in practice, it is always the most common few hundred types. The reason is that the most common supplements appear extremely frequently in training data, so they have a very high probability of being selected. |
| Consistency of Answers |
Fully Consistent
Trained on domain-specific data, the CNN+NLP+Domain-Specific NLP solution can more accurately understand domain terminology and context, thereby reducing inconsistent answers caused by semantic ambiguity. At the same time, its more modular design—including steps such as text representation, feature extraction, and classification/generation—makes the output of each module more controllable, thus improving overall consistency. Unlike the generative approach of LLMs, the CNN+NLP+Domain-Specific NLP solution relies more on rule-based or statistical models, producing more stable results that are less susceptible to minor input changes. In terms of answer consistency, the CNN+NLP+Domain-Specific NLP solution has an advantage over LLMs because it is more controllable, more stable, and can incorporate domain knowledge to reduce randomness. |
Inconsistent
Asking the same question about the same disease or demand multiple times in a row results in different recommended supplements each time. This is caused by the limitations of the model's training data and its mechanism of generating answers based on probabilities. The randomness that has to be introduced to prevent overfitting and improve generalization ability leads to inconsistent answers each time. On the other hand, reducing generalization ability causes the model to vacillate between multiple different patterns, resulting in different answers to the same question. |
| Data Sources |
Daza Matrix's data comes from a single data source (PubMed).
PubMed is the world's largest biomedical literature database. |
Extensive and heterogeneous sources. Mainly including three categories: internet text (various articles, news, posts, Q&A, advertisements, etc.), books from various fields, and literatures/papers from various fields. |
| Number of Literatures Analyzed in Real-Time at Once | 2,000 to several million pieces | Several dozen to several hundred pieces |
| Method of Retrieving PubMed Literatures During Real-Time Analysis |
Supports Chinese and English keyword searches, and automatically downloads all literatures retrieved. Literature data preprocessing and uploading are also fully automated.
All you need to do is enter keywords (names of diseases or demands), and Daza Matrix will automatically complete all AI analysis work. |
Requires manual downloading of literatures to be analyzed in advance via third-party tools. Additionally, you need to upload the downloaded literatures one by one manually or by calling LLM APIs programmatically.
Furthermore, even if you retrieve hundreds of thousands of eligible literatures or obtain hundreds of thousands of literatures to be analyzed, you can only upload several dozen to several hundred of them, as LLMs can only process this volume at once. |
| Ability to Directly Generate Formulas | Can directly generate top-tier formulas. For any disease or demand, Daza Matrix identifies the most effective species and supplements from over 2 million species and more than 100,000 supplements worldwide. By only adding the most effective candidate species and candidate supplements to the Custom Formula Pool, we completely eliminate the possibility of large language models choosing mediocre options. Then, let large language models directly generate top-tier formulas based on your Custom Formula Pool. When using My Super Formulas (Custom Formula Pool), you can not only specify which species/supplements are added to the formula pool, but also fully control the final generated formula by setting Mandatory Ingredients, Number of Ingredients, Target Species, and Special Instructions. | Can only directly generate mediocre formulas. It constructs formulas by selecting relatively effective (and sometimes completely ineffective) supplements from the most common few hundred types of supplements. |
Super Member Privileges
-
Super Membership is suitable for:
1. Enterprises, institutions, and individuals who need to identify the most effective species and supplements from global species and global supplements for any disease or demand.
2. Enterprises, institutions, and individuals engaged in the R&D of formulas for supplements, health supplements, pharmaceuticals, and functional foods.
3. Enterprises, institutions, and individuals who want to conduct in-depth, full-perspective exploration of the effects of food, supplements, and pharmaceuticals on demands and diseases.
4. Enterprises, institutions, and individuals who want to inspire and pinpoint the pathogenesis and therapeutic mechanisms of any disease or demand.
-
1. Daza Matrix – Semantic-level Knowledge Graph (Semantic-level Word Frequency).
-
Semantic-level Word Frequency analyzes the true word frequency of literatures based on Named Entity Recognition (NER), Part-of-Speech Analysis, Root Extraction, and TF-IDF derived from Natural Language Processing (NLP), as well as factors such as the impact factor value of the journal to which the literature belongs and the literature type. This enables you to quickly discover the truly important terms and information contained in massive volumes of literatures.
Semantic-level Word Frequency analysis is divided into two types: one analyzes the titles and abstracts of literatures; the other analyzes the keywords and Medical Subject Headings (MeSH) of literatures. Both types of word frequency analysis are presented in both Chinese and English to facilitate reading and comparison.
Semantic-level Word Frequency provides three display forms: one bar chart and two word clouds.
-

-
2. Daza Matrix – Semantic-level Knowledge Graph (Species Name Recognition).
-
Species Name Recognition, based on FoodWake's curated Global Species Library and Convolutional Neural Networks (CNN), identifies all existing species mentioned in massive volumes of literatures and performs semantic-level word frequency sorting on the recognized species names.
In fact, this function can not only accurately identify all existing species but also recognize newly discovered species names in the future. A species name, also known as the scientific name, Latin name, binomial nomenclature, or Linnaean name of a species. FoodWake's curated Global Species Library has included over 290,000 genera and more than 2 million species.
Essentially, for a disease or demand keyword, the Species Name Recognition function enables you to discover the most effective species for treating the disease or addressing the demand among global species.
All recognized species names are presented in both Chinese and English for easy viewing and comparison.
-
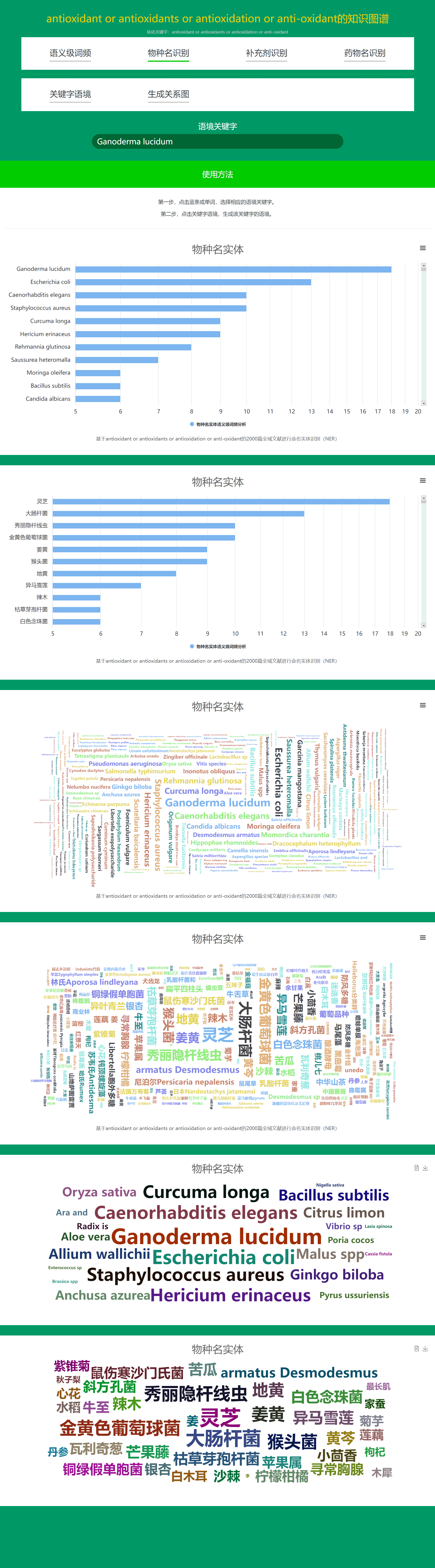
-
3. Daza Matrix – Semantic-level Knowledge Graph (Supplement Recognition).
-
Supplement Recognition, based on FoodWake's curated Global Supplement Library and Convolutional Neural Networks (CNN), identifies all existing supplements mentioned in massive volumes of literatures and performs semantic-level word frequency sorting on the recognized supplements.
In fact, this function can not only accurately identify all existing supplements but also recognize newly discovered supplements in the future. FoodWake's curated Global Supplement Library has included over 100,000 types of supplements.
Essentially, for a disease or demand keyword, the Supplement Recognition function enables you to discover the most effective supplements for treating the disease or addressing the demand among global supplements.
All recognized supplements are presented in both Chinese and English for easy viewing and comparison.
-
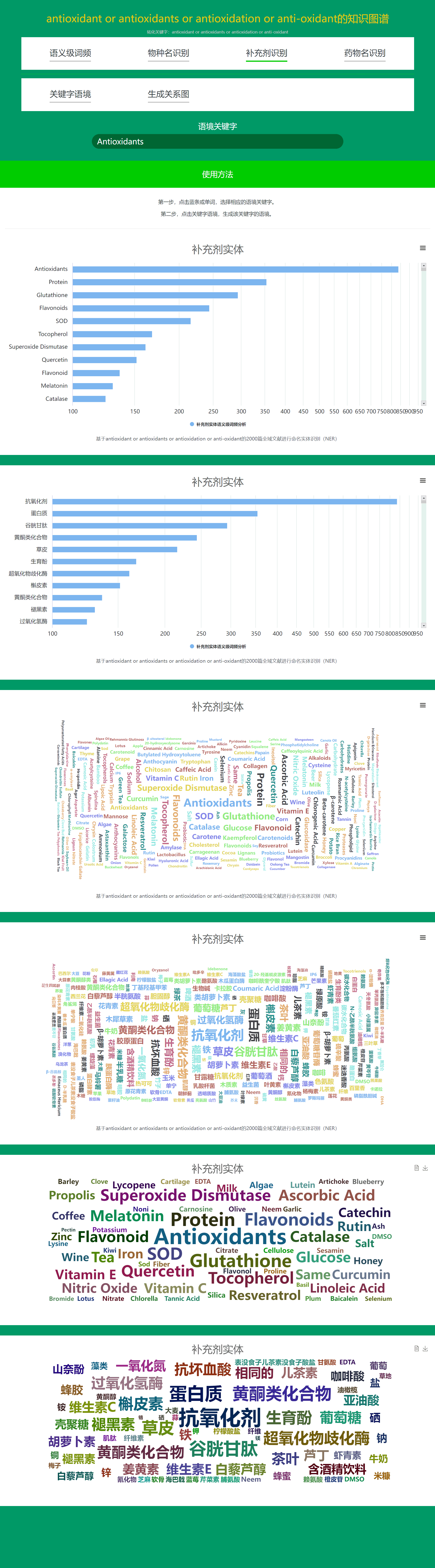
-
4. Daza Matrix – Semantic-level Knowledge Graph (Disease Name Recognition).
-
Disease Name Recognition, based on the Global Disease Name Library built on the International Classification of Diseases (ICD) and Convolutional Neural Networks (CNN), identifies all existing disease names mentioned in massive volumes of literatures and performs semantic-level word frequency sorting on the recognized disease names.
In fact, this function can not only accurately identify all existing disease names but also recognize newly discovered disease names in the future. The Global Disease Name Library has included over 66,000 disease names.
Essentially, for a species or supplement keyword, the Disease Name Recognition function enables you to discover which diseases the species or supplement is most effective at treating among global disease names.
All recognized disease names are presented in both Chinese and English for easy viewing and comparison.
-
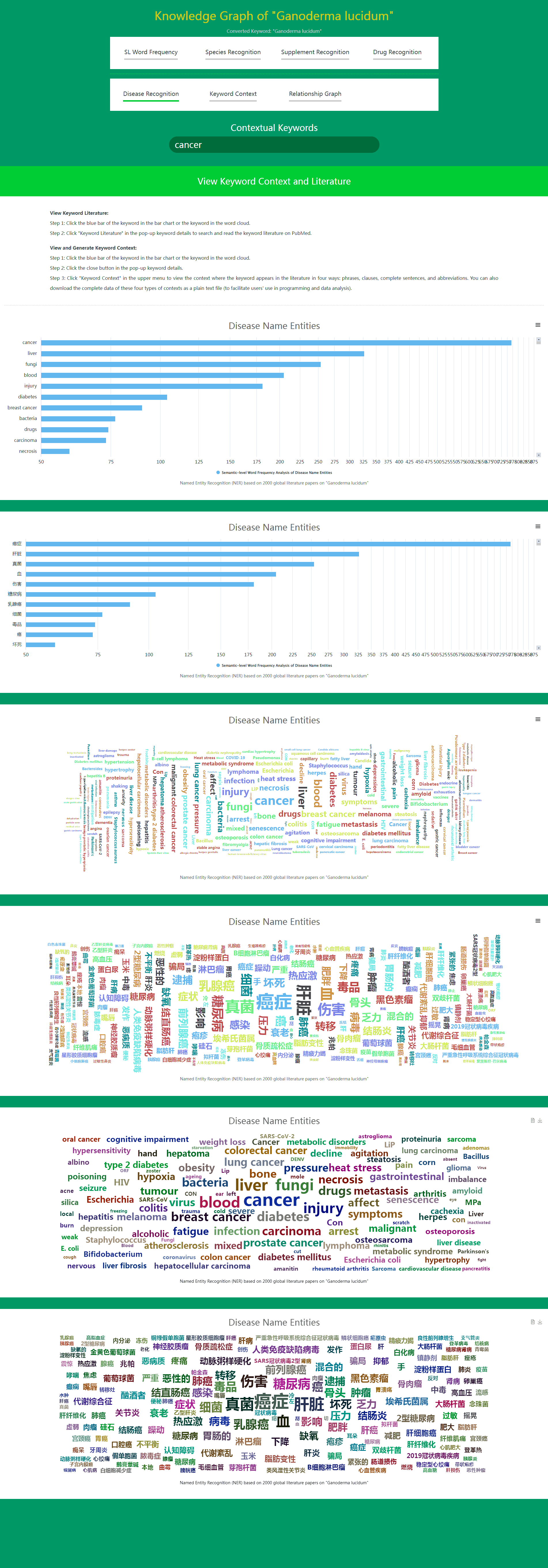
-
5. Daza Matrix – Semantic-level Knowledge Graph (Keyword Context).
-
Keyword Context: After discovering a term, species, supplement, or disease name that interests you in Semantic-level Word Frequency, Species Name Recognition, Supplement Recognition, or Disease Name Recognition, you will certainly want to know the context (i.e., the contextual environment) in which the term, species, supplement, or disease name appears in the literatures.
Simply click on the term, species, supplement, or disease name in Semantic-level Word Frequency, Species Name Recognition, Supplement Recognition, or Disease Name Recognition, then click Keyword Context to view the context of the term, species, supplement, or disease name in the literatures in four ways: Phrases, Clauses, Complete Sentences, and Abbreviations. Among them, Abbreviations are reconstructed abbreviated forms after parsing complete sentences according to grammatical structures.
In addition to the four types of contexts, super analysis of the term, species, supplement, or disease name is also provided in two ways: bar charts and semantic-level word clouds. The complete data of the four types of contexts is available for download as a plain text file.
-

-
6. Daza Matrix – Semantic-level Knowledge Graph (Relationship Graph Generation).
-
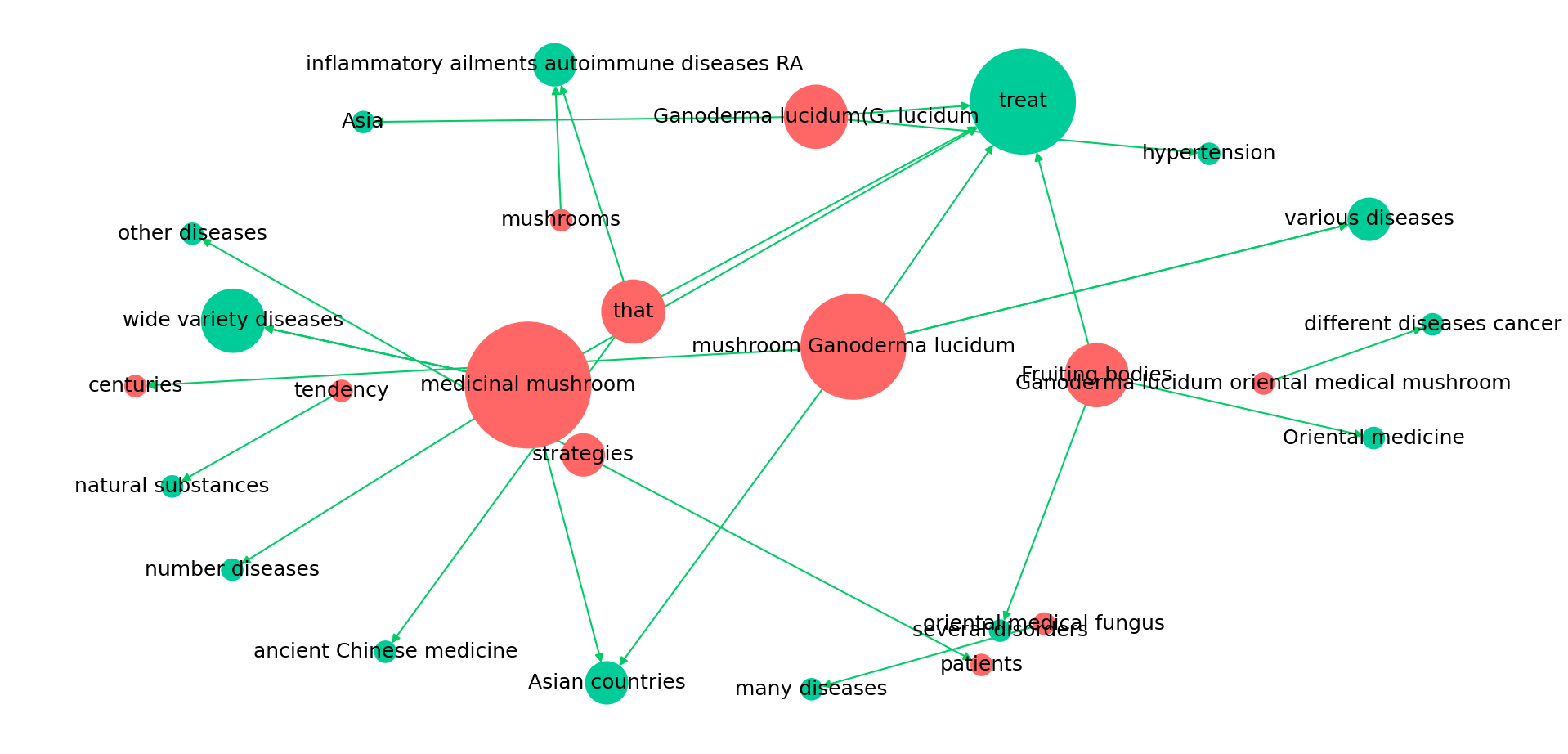
Relationship Graph Generation can be regarded as a graphical version of the Abbreviation method in Keyword Context.
For example, if you have generated a knowledge graph for antioxidation, and you found Ganoderma lucidum in Species Name Recognition. At this time, when you click Relationship Graph Generation, you will see interesting verbs such as "used" and "concluded" appearing in the generated relational verb list sorted by word frequency.
Now, simply click "used" in the verb list and then click Relationship Graph Generation, and a relationship graph will be generated with Ganoderma lucidum as the subject, "used" as the relationship, and any entity parsed from the full-sentence abbreviations as the target.
-
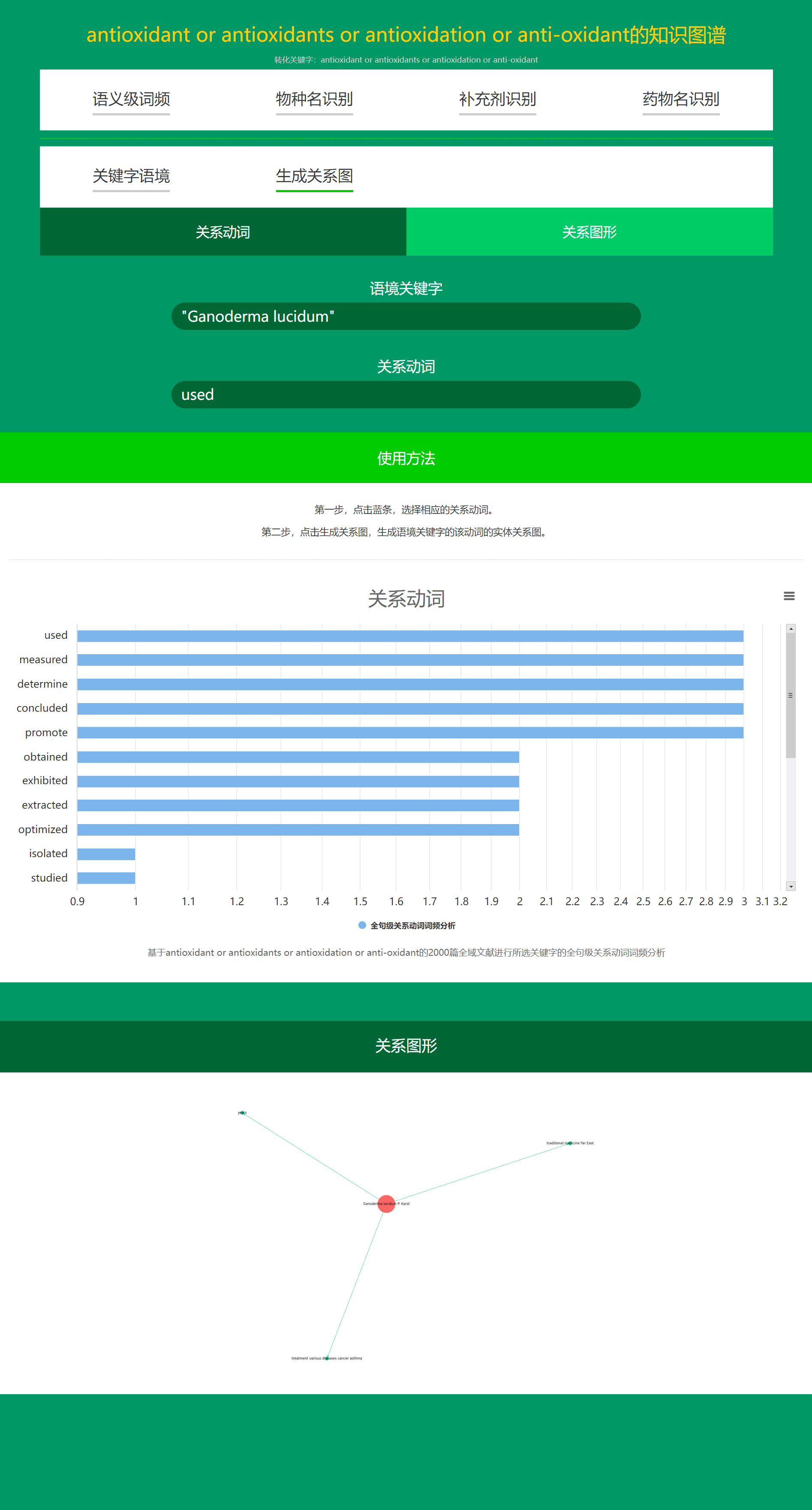
-
The more literatures collected, the more complex the generated relationship graph will be.
-
-
7. Daza Matrix – Semantic-level Knowledge Graph (Real-time PubMed Search).
-
Data (Literatures) for Semantic-level Knowledge Graph is obtained by real-time searching PubMed, the world's largest biomedical literature database.
The Semantic-level Knowledge Graph directly calls the PubMed API and supports all PubMed search Boolean operators, parentheses, and double quotes. This allows you to combine and build keyword search logic ranging from the simplest and easiest to use to the most complex and powerful, and keywords support full English, full Chinese, and mixed Chinese-English searches.
FoodWake's Semantic-level Knowledge Graph – Daza Matrix is a powerful AI tool for you to find natural therapeutic species and supplements for diseases and demands; a powerful AI tool to quickly master and understand important information about any term, species, and supplement; a powerful AI tool to query the efficacy, application fields, and side effects of any drug, supplement, food, or food additive.
-

-
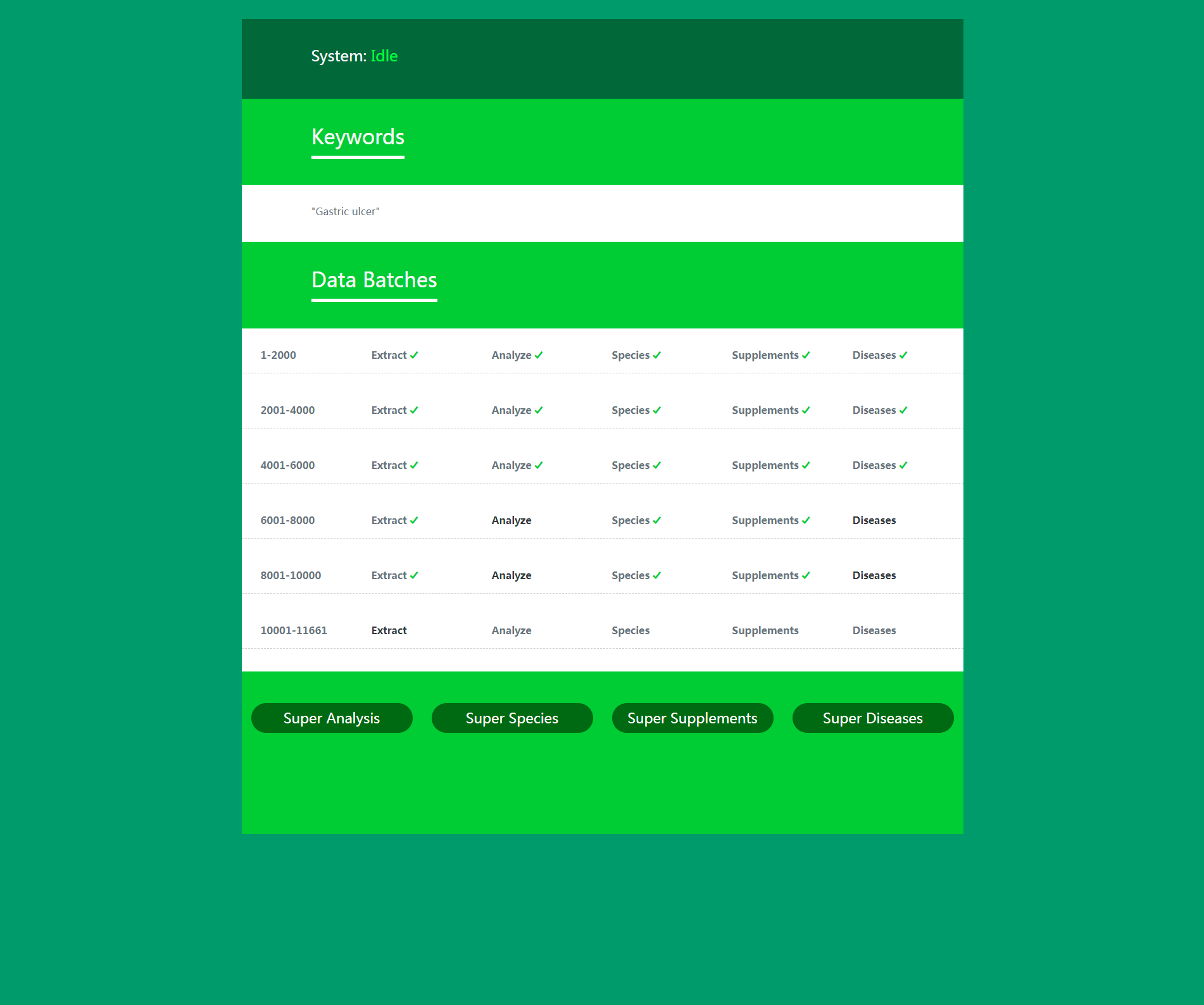
8. Daza Matrix – Super Semantic-level Knowledge Graph (Super Data, Super Analysis, Super Species, Super Supplements, and Super Diseases).
-
Data (Literatures) for Semantic-level Knowledge Graph is obtained by real-time searching PubMed, the world's largest biomedical literature database. For any keyword combination, the top 2000 most relevant literatures are extracted from all eligible literatures retrieved from PubMed using Best Match sorting by default. The Semantic-level Knowledge Graph will be analyzed and constructed based on these 2000 literatures.
(1) Super Data
For some keyword combinations, the number of all eligible literatures retrieved from PubMed may far exceed 2000. For example, when you use the keyword "antioxidant" to generate a semantic-level knowledge graph related to antioxidants, the number of eligible literatures returned by PubMed will exceed 700,000. In this case, using only 2000 literatures for data analysis will obviously result in incomplete analysis results. Therefore, you will want to analyze and construct the semantic-level knowledge graph based on a larger number of literatures.
Daza Matrix meets this need by providing Super Data and Super Analysis. To break through the limit of 2000 literatures, you need to use Super Data.
-

-
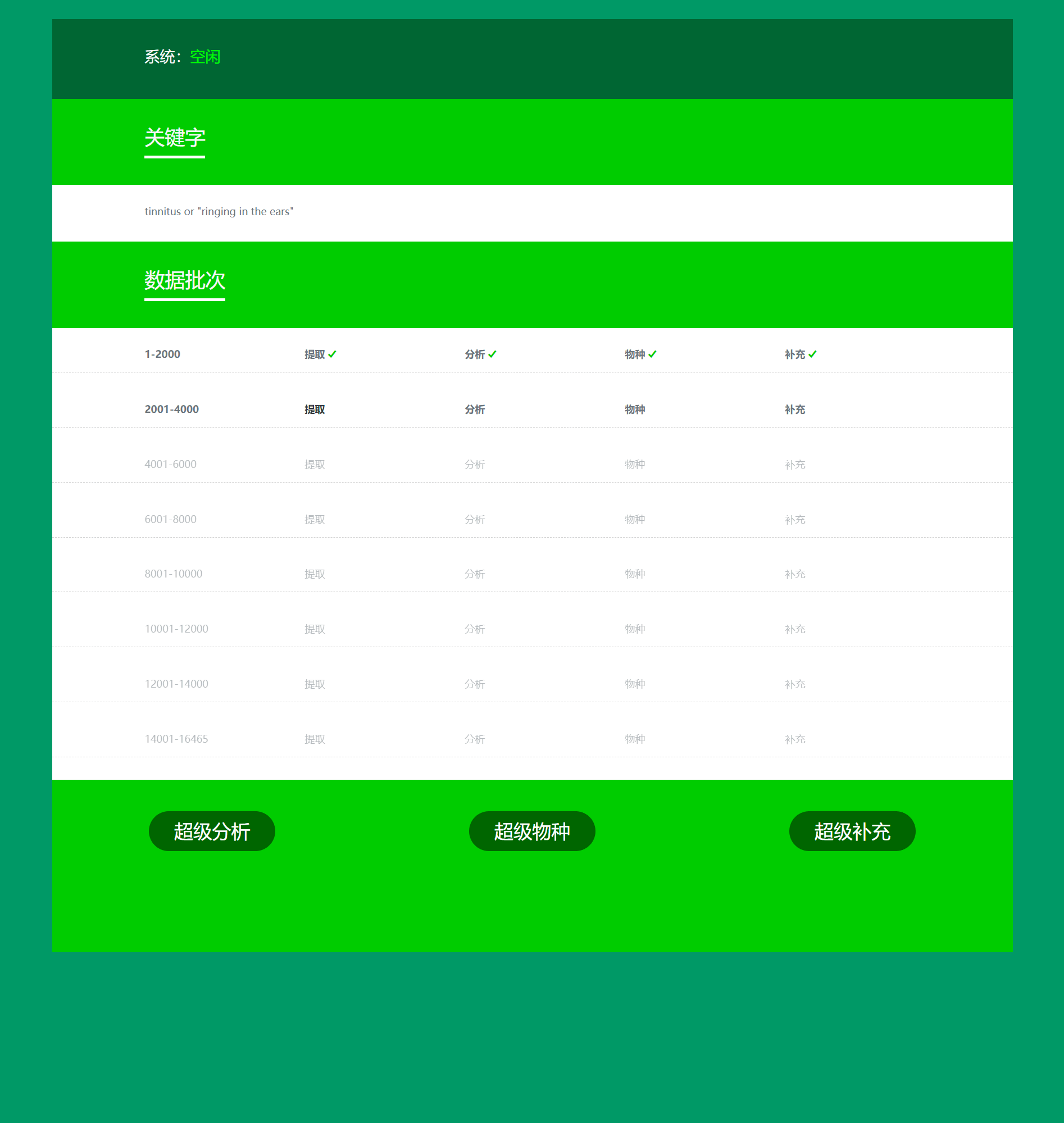
Super Data breaks through the 10,000-record limit of the PubMed API through a batch retrieval and acquisition mechanism. Regardless of whether the number of eligible retrieved literatures is tens of thousands, hundreds of thousands, or even millions, all can be fully acquired.
(2) Super Analysis
Combined with Super Data's batch retrieval and acquisition mechanism, Super Analysis can efficiently generate super semantic-level knowledge graphs (Super Semantic Analysis, Super Species Recognition, Super Supplement Recognition, Super Disease Recognition, Super Keyword Context) for hundreds of thousands of literatures through a batch processing mechanism.
(3) Super Species and Super Supplements
When Daza Matrix completes all data batches, based on FoodWake's curated Global Species Library, Global Supplement Library, and Convolutional Neural Networks (CNN), combined with Correlation Coloring implemented by LLM/LSTM+SHA, it can find the most effective Super Species and Super Supplements for your current demands and diseases.
(4) Super Diseases
When Daza Matrix completes all data batches, based on the Global Disease Name Library and Convolutional Neural Networks, you can view a complete graph of which diseases the current species or supplement is most effective at treating.
(5) Batch Retrieval and Acquisition Mechanism
Through the batch retrieval and acquisition mechanism of Super Data, you can generate Super Analysis results, Super Species results, Super Supplement results, and Super Disease results based on the currently completed data batches at any time without finishing all data batches. Moreover, as you complete more data batches, you can see that the generated Super Analysis results, Super Species results, Super Supplement results, and Super Disease results are changing accordingly. When you complete all data batches, you can generate the final and decisive Super Analysis results, Super Species results, Super Supplement results, and Super Disease results.
-
-
(6) Number of Literatures That Can Be Processed
When using Super Data, for each group of keywords, Super Members will process all literatures if the number of literatures to be acquired and analyzed does not exceed 30,000. When the number of literatures exceeds 30,000, Super Members will process 20% of them. Super Member Max, on the other hand, can process 100% of all literatures for any group of keywords.
For example, if a keyword combination retrieves 500,000 literatures, Super Member will process 100,000 literatures, and Super Member Max will process 500,000 literatures.
-
9. Daza Matrix – Super AI Diet Therapy.
-
For any disease or demand, identify the most effective species and supplements from over 2 million species worldwide and over 100,000 types of supplements.
(1) Super AI Diet Therapy
For any disease or demand, identify the most effective species and supplements from over 2 million species worldwide and over 100,000 types of supplements.
The Super AI Diet Therapy function is realized through Daza Matrix's Species Name Recognition and Supplement Recognition. Based on FoodWake's curated Global Species Library, Global Supplement Library, and Convolutional Neural Networks (CNN), combined with Correlation Coloring implemented by LLM/LSTM+SHA, it identifies all existing species and supplements mentioned in massive volumes of literatures, and performs semantic-level word frequency sorting and correlation coloring on the recognized species names and supplements. This makes the most effective species and supplements for the disease or demand stand out and be easily understood at a glance.
(2) Custom Diseases and Demands
With the Super AI Diet Therapy function, you can customize any disease or demand.
Using Super AI Diet Therapy, you can find the most effective species and supplements worldwide for the following demands and diseases:
- Anti-Aging
- Life Extension
- IQ Enhancement
- Memory Improvement
- Anti-Cancer
- Alzheimer's Disease (Senile Dementia)
- Diabetes
- Anxiety Disorder
- Depression
- Weight Loss
- Height Increase
- Insomnia
- Antioxidation
- Telomere Extension
- ……
- More Custom Demands Defined by You
(3) Demands and Sub-Demands
Each demand or disease can be treated as a whole, or subdivided into multiple sub-demands as needed. For example, "Memory Improvement" can be treated as a single entity, or subdivided into sub-demands such as Cognitive Ability Enhancement, Spatial Memory Improvement, Cerebral Blood Flow Increase, Attention Enhancement, Neuroprotection, Neuroregeneration, Promotion of Neuron Proliferation, and Anti-Oxidative Stress.
Another example: "Telomere Extension" can be treated as a whole, or subdivided into sub-demands such as Antioxidation (combating oxidative stress damage to telomeres), Anti-Anxiety and Anti-Depression (stress accelerates telomere shortening), DNA Repair, and Telomerase Activation (excessive telomerase activation increases cancer risk, so telomerase should be activated on the premise of inhibiting cancer).
(4) Keyword Support
Simply enter keywords (or keyword groups) for demands or diseases, and Super AI Diet Therapy will identify the most effective species and supplements from over 2 million species worldwide and over 100,000 types of supplements for you. Whether you are analyzing a demand (e.g., Memory Improvement), a sub-demand (e.g., Neuroprotection under Memory Improvement), or a disease along with its complications and secondary diseases, Super AI Diet Therapy will real-time retrieve and analyze massive volumes of PubMed literatures and quickly provide you with answers.
Keyword support includes full English, full Chinese, and mixed Chinese-English inputs. It also supports all PubMed search Boolean operators, as well as parentheses and double quotation marks. This allows you to combine and construct keyword search logic ranging from the simplest and easiest to use to the most complex and powerful, accurately obtaining the required literatures.
(5) Eliminate Hallucinations
Super AI Diet Therapy adopts NLP+Domain-Specific NLP+Convolutional Neural Network models to effectively eliminate hallucinations in Large Language Models (LLMs) when analyzing literatures.
-
10. Daza Matrix – Semantic-level Knowledge Graph (View Keyword Literatures).
-
You can conveniently view literatures for keywords you are interested in at any time in Semantic-level Word Frequency, Species Name Recognition, Supplement Recognition, and Disease Name Recognition of the Semantic-level Knowledge Graph, as well as in Super Analysis, Super Species, Super Supplements, and Super Diseases of the Super Semantic-level Knowledge Graph.
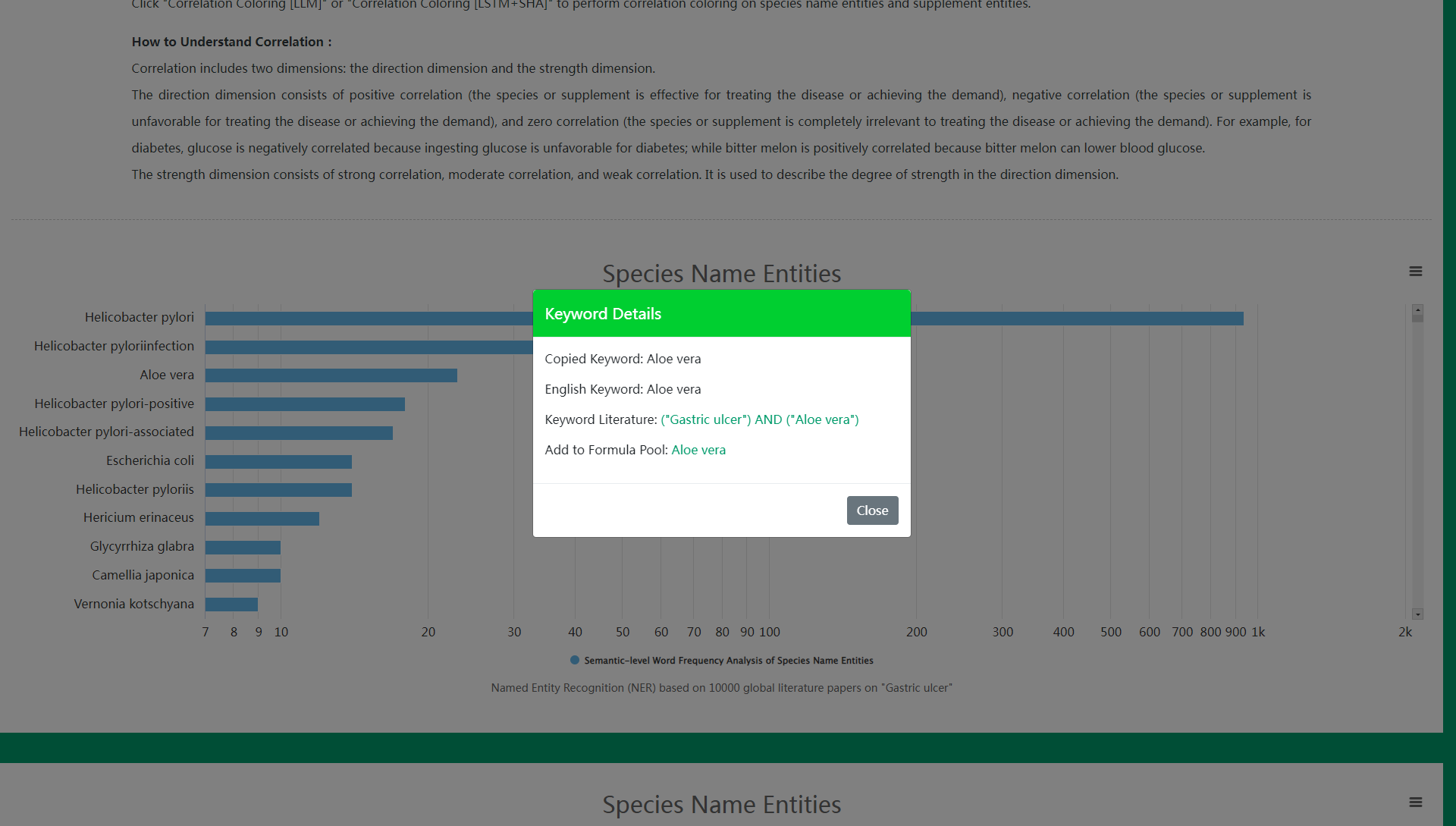
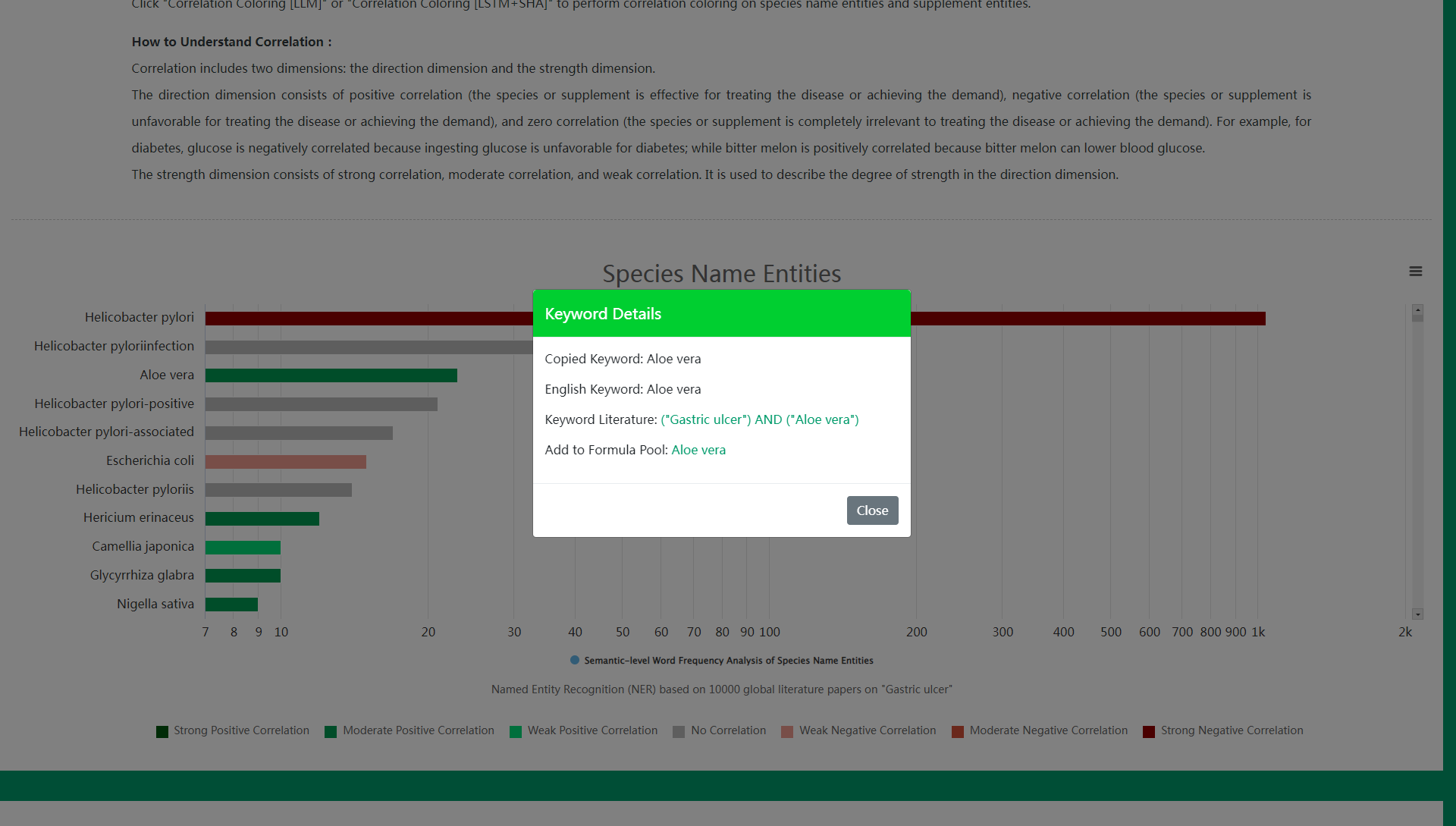
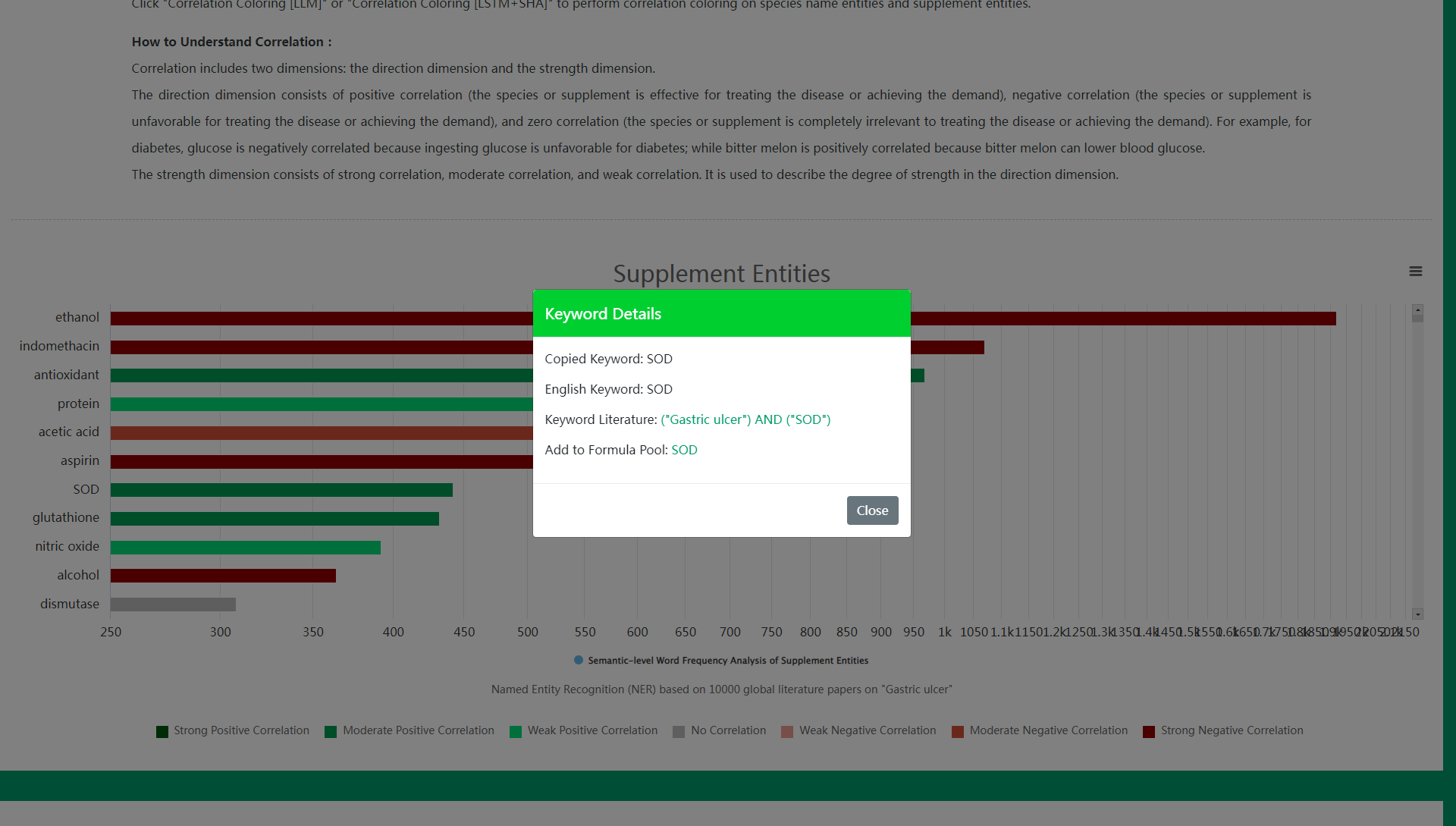
(1) View Keyword Literatures
Step 1: Click the blue bar of the keyword in the bar chart or the keyword in the word cloud.
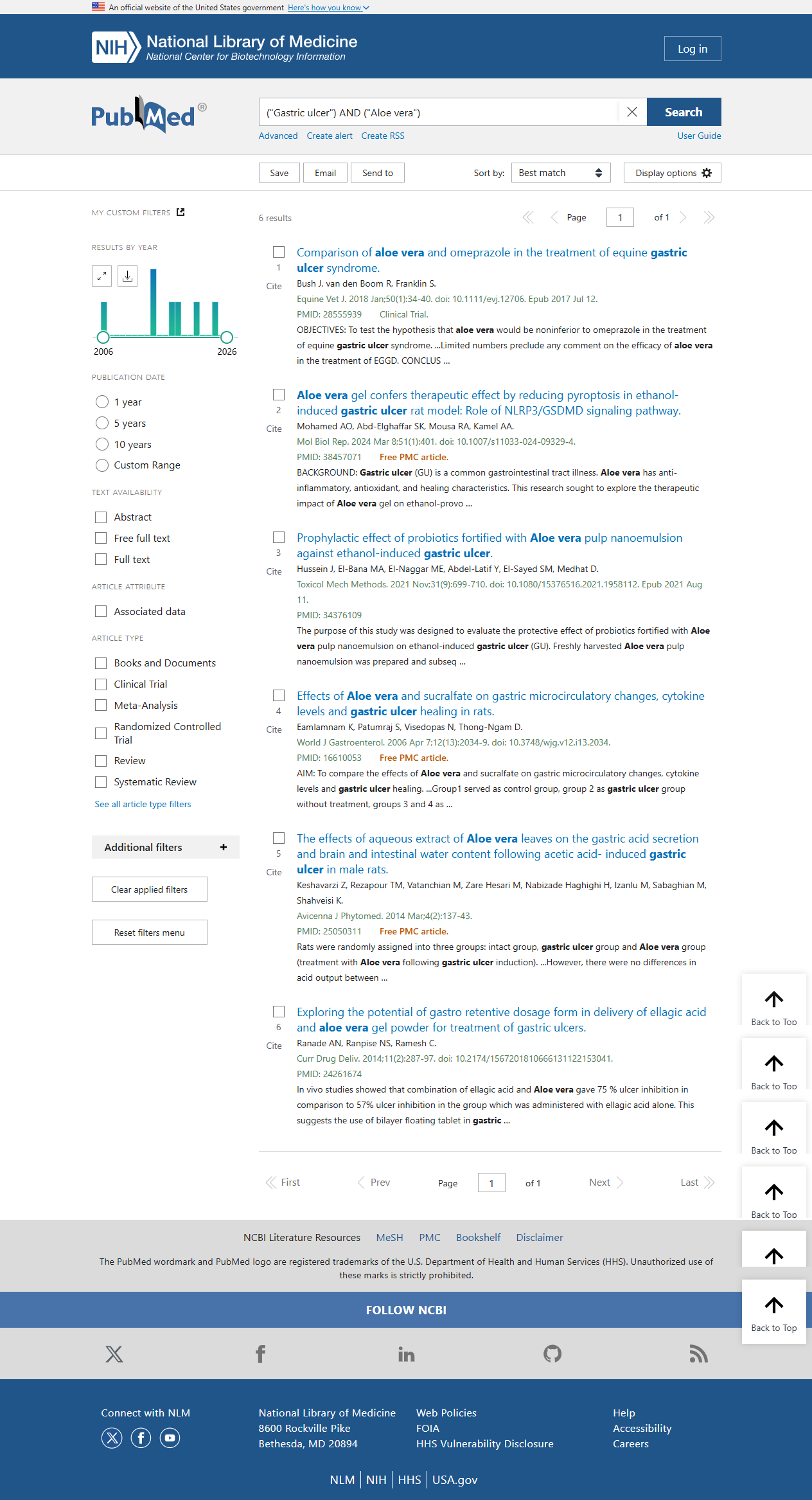
Step 2: Click Keyword Literatures in the pop-up keyword details to search and read literatures related to the keyword on PubMed.
-
-
-
(2) View and Generate Keyword Context
Step 1: Click the blue bar of the keyword in the bar chart or the keyword in the word cloud.
Step 2: Click the Close button in the pop-up keyword details.
Step 3: Click Keyword Context in the top menu to view the context of the keyword in the literatures in four ways: Phrases, Clauses, Complete Sentences, and Abbreviations. The complete data of the four types of contexts can be downloaded as a plain text file (for users to use in programming and data analysis).
-

-
11. Daza Matrix – Large Language Model Formula Design.
-
You can select a Large Language Model to combine with the analysis results of FoodWake's Daza Matrix. Select the most effective species and supplements from over 2 million species worldwide + over 100,000 types of supplements worldwide, and combine the Large Language Model's capabilities in knowledge integration and retrieval, logical reasoning and analysis, data processing and prediction, and risk avoidance and ethical boundary control to generate complete formulas with significant effects, safety and reliability, full-path multi-target, and multi-path multi-mechanism synergy based on medical literatures.
Currently supports the world's top ten large language models: Claude-Opus-4.7, Claude-Opus-4.6-Thinking, GPT-5.5, GPT-5.4, Gemini-3.1-Pro-Preview, Gemini-3-Flash-Preview, DeepSeek-V4-Pro, DeepSeek-V4-Flash, Doubao-Seed-2.0-pro, Doubao-Seed-2.0-lite.
-
-

-
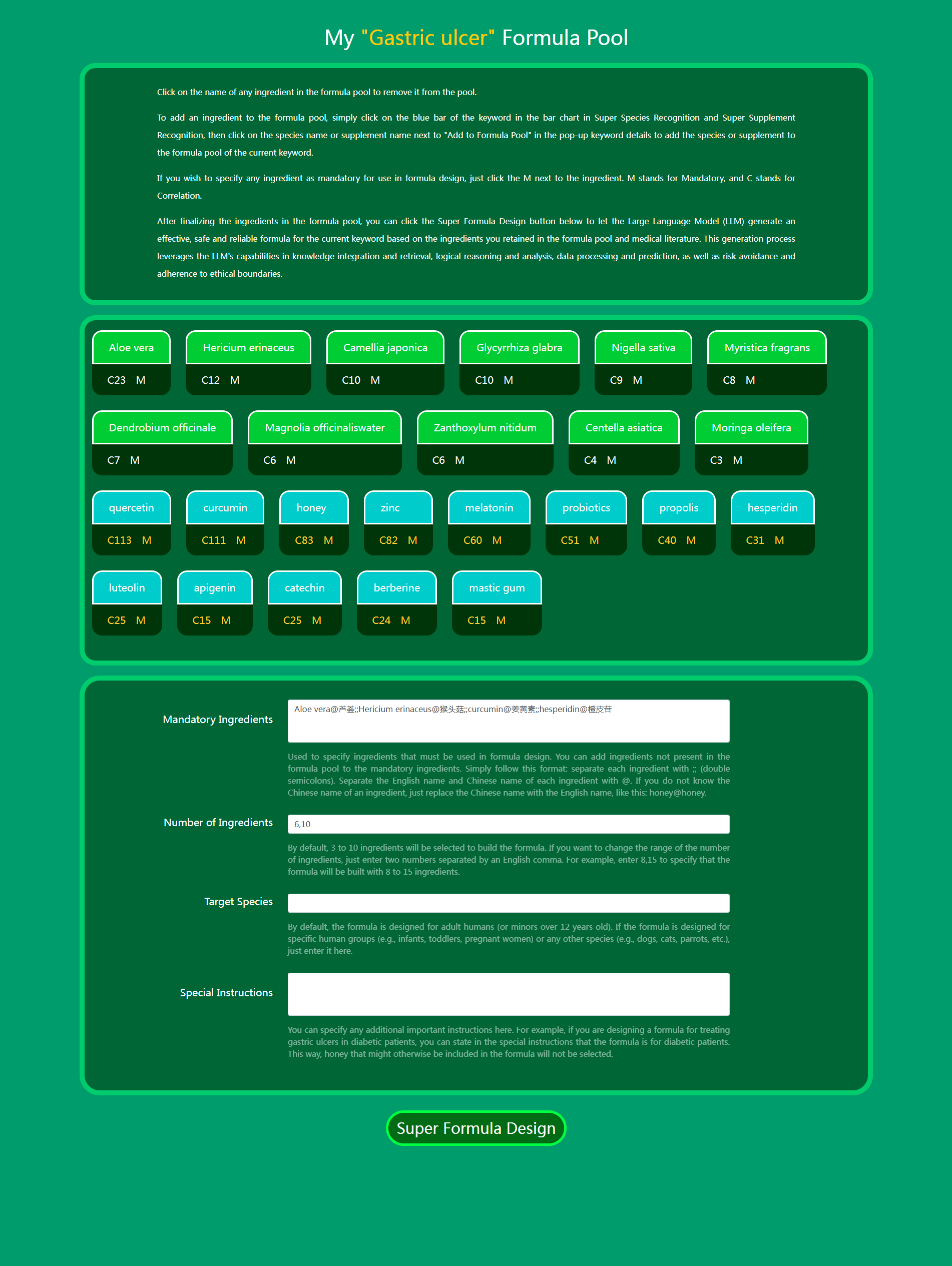
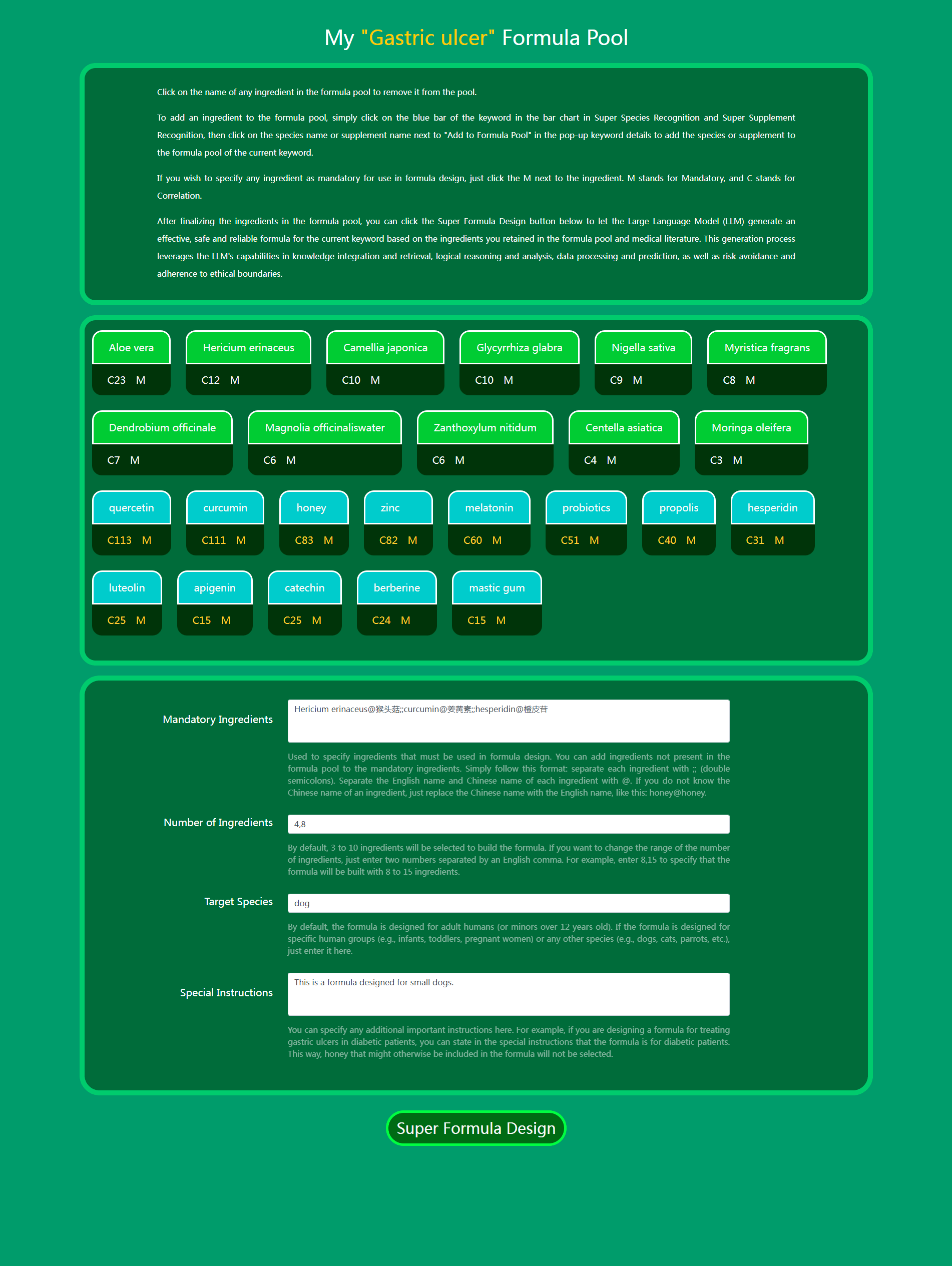
12. Daza Matrix – My Super Formulas (Custom Formula Pool).
-
Using My Super Formulas (Custom Formula Pool) in Daza Matrix's Super Data, you can further select the ingredients you most want to use from Super Species Recognition and Super Supplement Recognition to build your own formula pool. By using Correlation Coloring to clearly view the correlation between species/supplements and diseases or demands, and consulting literature titles and abstracts as needed, you can easily select the most effective species and supplements and add them to your Custom Formula Pool. Then, let the Large Language Model generate top-tier formulas directly based on your formula pool. Compared with directly using Super Formula Design (i.e., Large Language Model Formula Design of Daza Matrix), My Super Formulas (Custom Formula Pool) allows you to more precisely construct formula ingredients and generate top-tier formulas with the ingredients you most want to use.
Currently supports the world's top ten large language models: Claude-Opus-4.7, Claude-Opus-4.6-Thinking, GPT-5.5, GPT-5.4, Gemini-3.1-Pro-Preview, Gemini-3-Flash-Preview, DeepSeek-V4-Pro, DeepSeek-V4-Flash, Doubao-Seed-2.0-pro, Doubao-Seed-2.0-lite.
When using My Super Formulas (Custom Formula Pool), you can not only specify which species/supplements are added to the formula pool but also fully control the final generated formula by setting Mandatory Ingredients, Number of Ingredients, Target Species, and Special Instructions.
(1) Mandatory Ingredients
Used to specify ingredients that must be used in formula design. You can even add ingredients not present in the formula pool to Mandatory Ingredients. Simply follow this format: separate each ingredient with ;; , and separate the English name and Chinese name of each ingredient with @ . If you do not know the Chinese name of an ingredient, just replace the Chinese name with the English name, like this: honey@honey.
(2) Number of Ingredients
3 to 10 ingredients will be selected to build the formula by default. If you want to change the range of the number of ingredients, just enter two numbers separated by an English comma. For example, enter 8,15 to specify that the formula will be built using 8 to 15 ingredients.
(3) Target Species
The formula is designed for human adults (or minors over 12 years old) by default. If the formula is designed for a specific period of human life (e.g., infants, toddlers, pregnant women) or for any other species (e.g., dogs, cats, parrots, etc.), simply enter it here.
(4) Special Instructions
You can specify any additional important instructions here. For example, if you are designing a formula for treating gastric ulcers for patients with diabetes, you can state in Special Instructions that the formula is for diabetic patients. This way, honey that might otherwise be included in the formula will not be selected.
-
-
-
-
-
-
-
-

-
13. Daza Matrix – Formula Design for Any Species (e.g., Dogs, Cats) or Specific Human Stages (e.g., Infants, Pregnant Women).
-
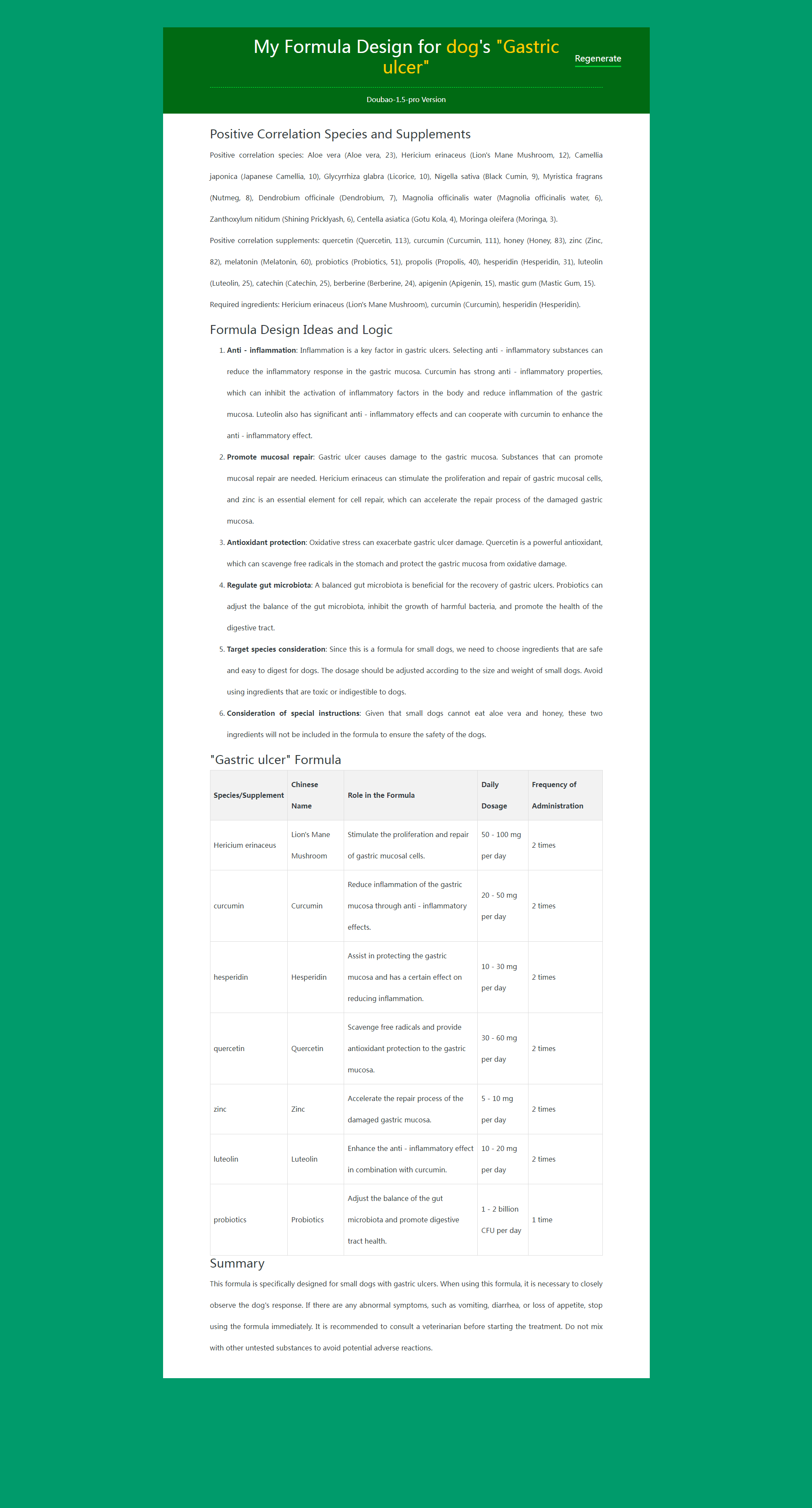
Use My Super Formulas (Custom Formula Pool) to design a gastric ulcer formula for small dogs.
-
-
-
14. Daza Matrix – Super Semantic-level Knowledge Graph (Correlation Coloring for Super Species and Super Supplements).
-
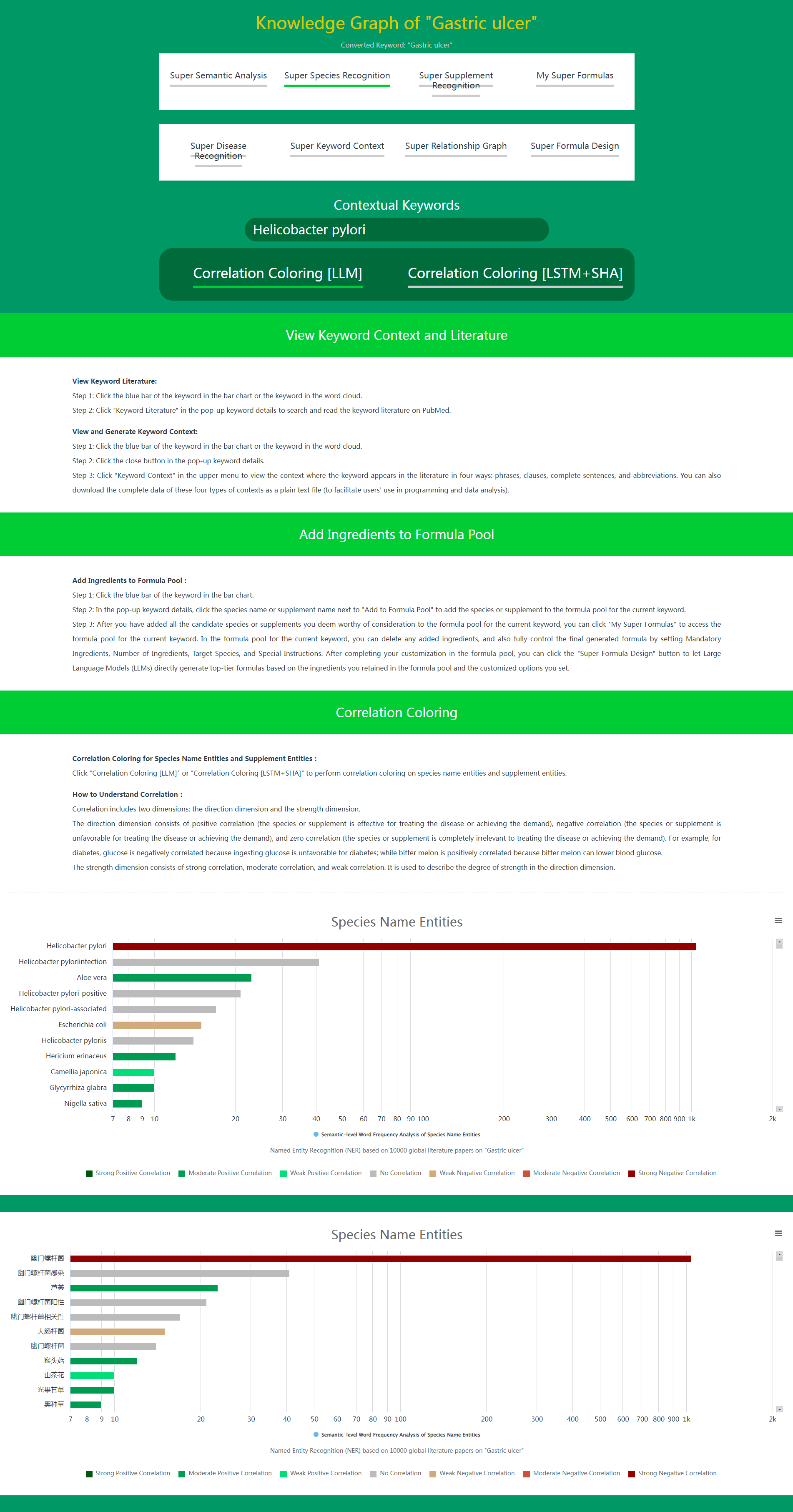
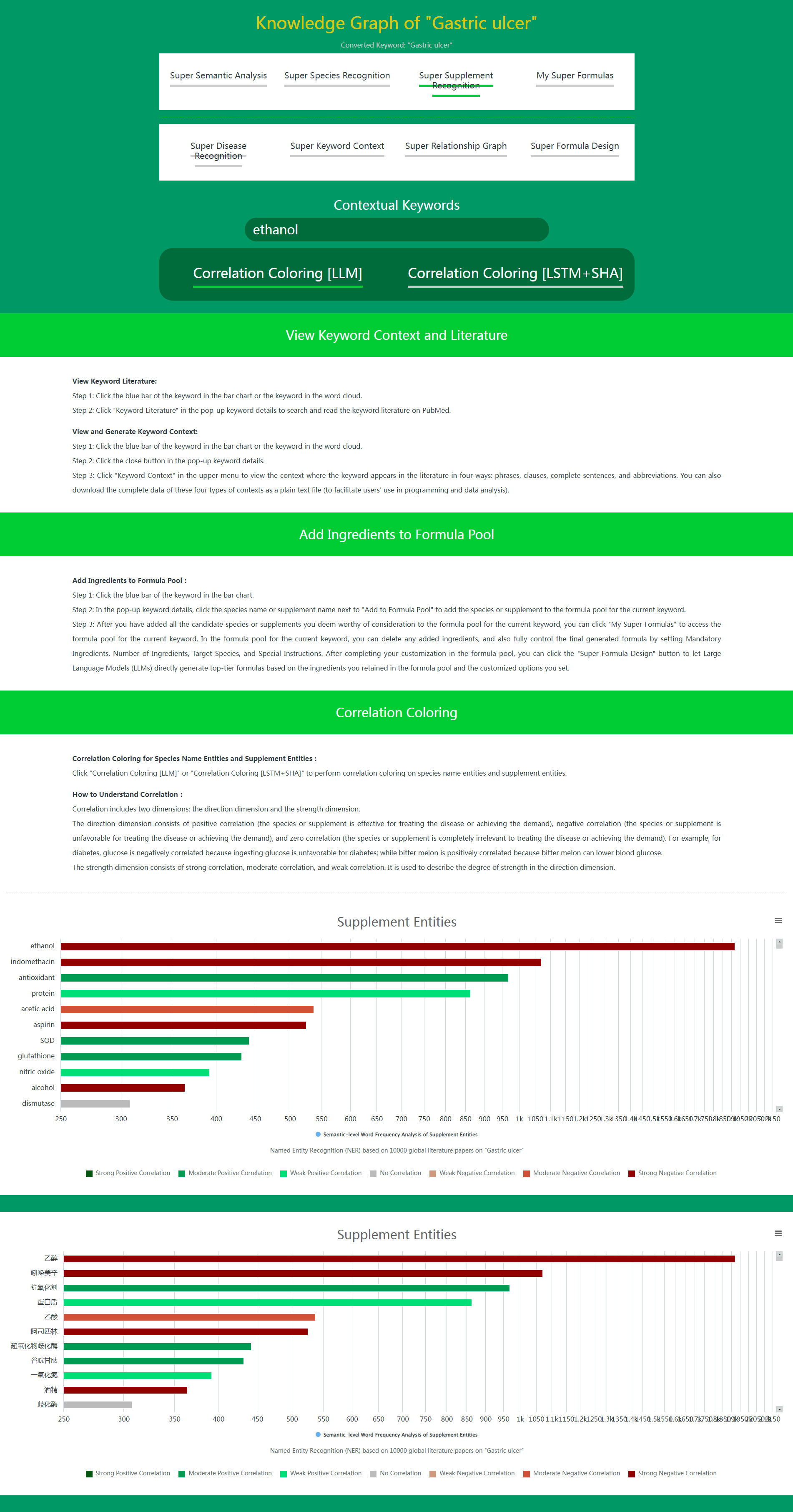
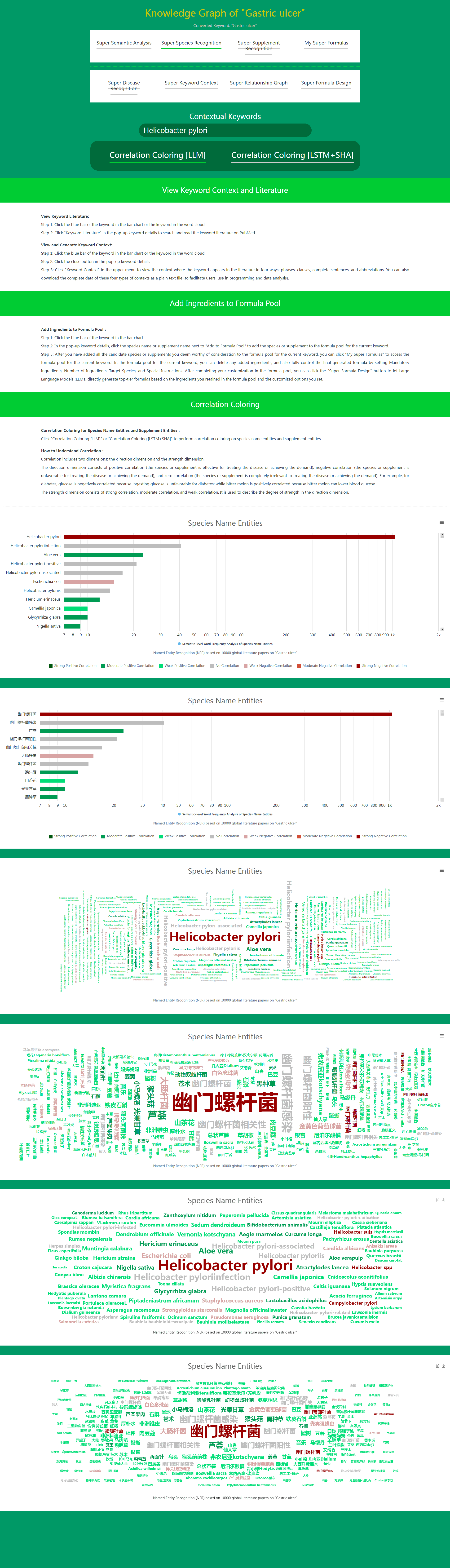
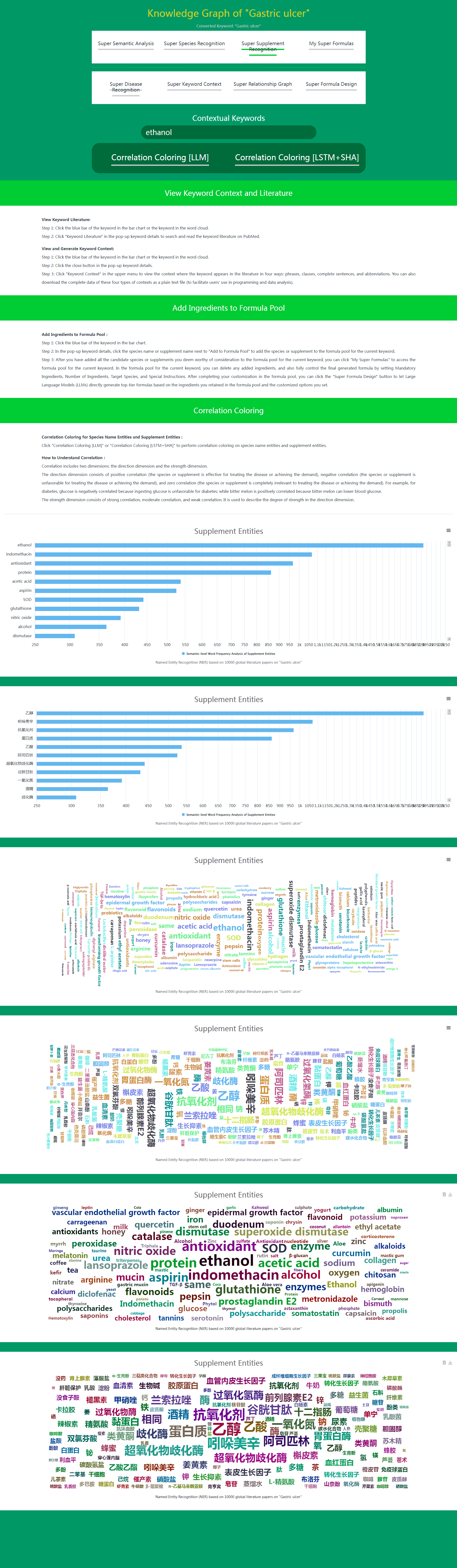
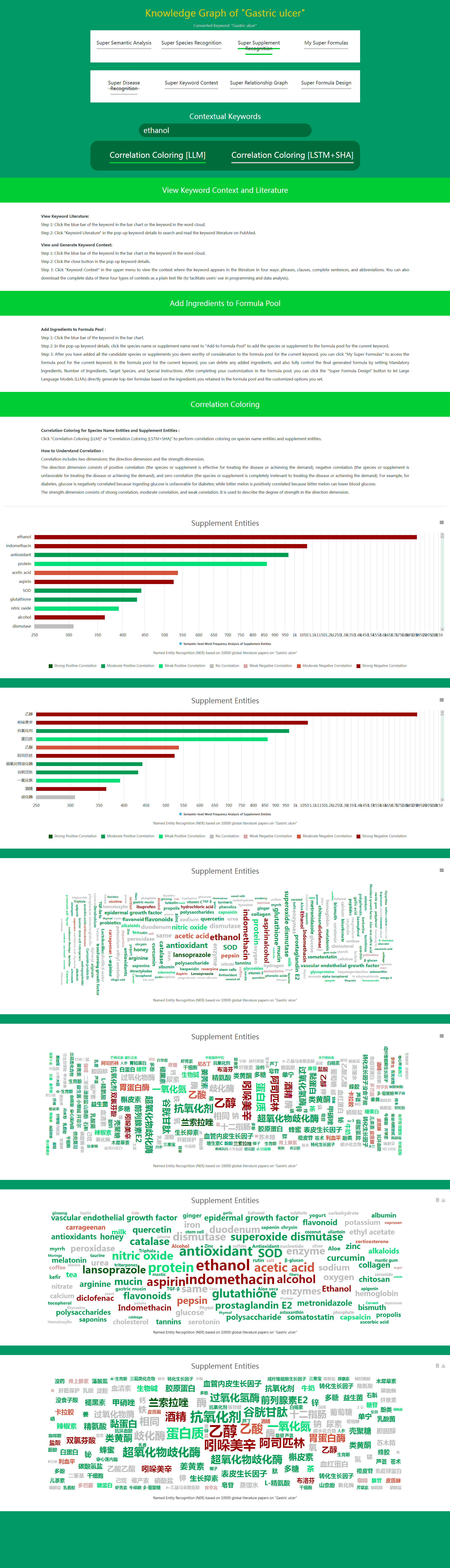
When using Super Species Recognition and Super Supplement Recognition in Daza Matrix's Super Data, you only need to click Correlation Coloring [LLM] or Correlation Coloring [LSTM+SHA] to perform correlation coloring on species name entities and supplement entities.
(1) How to Understand Correlation
Correlation includes two dimensions: direction and strength.
The direction dimension includes positive correlation (species or supplements are effective for treating the disease or meeting the demand), negative correlation (species or supplements are unfavorable for treating the disease or meeting the demand), and zero correlation (species or supplements are completely irrelevant for treating the disease or meeting the demand). For example, for diabetes, glucose is negatively correlated because intake of glucose is unfavorable for diabetes; while bitter melon is positively correlated because it can lower blood sugar.
The strength dimension includes strong correlation, moderate correlation, and weak correlation. It is used to describe the degree of strength in the direction dimension.
(2) What is the Function of Correlation Coloring
In Super Species Recognition and Super Supplement Recognition, species and supplements closely related to the current disease or demand are listed (sorted by semantic-level word frequency) in species name entities and supplement entities. This correlation includes both positive correlation (effective for treating the disease or meeting the demand) and negative correlation (unfavorable for treating the disease or meeting the demand).
In most cases, users with certain nutritional or medical knowledge can easily distinguish which species and supplements are positively correlated with the disease or demand, and which are negatively correlated. However, it is somewhat difficult for users lacking nutritional or medical knowledge. Of course, you can click on the blue bar of the species or supplement, and click Keyword Literatures in the pop-up keyword details to quickly check the literature title to determine whether the species or supplement is positively or negatively correlated with the disease or demand. But for users lacking nutritional or medical knowledge, if you find that you need to check the literature title for most species or supplements to determine positive or negative correlation, this method is inevitably inefficient.
In this case, Correlation Coloring can play its efficient role. By clicking Correlation Coloring, all species and supplements listed in species name entities and supplement entities will be colored differently according to whether they are positively or negatively correlated. Positive correlation is indicated in green, and negative correlation is indicated in reddish brown. At the same time, three shades of green represent three levels of positive correlation strength. Three shades of reddish brown represent three levels of negative correlation strength.
The combination of Semantic-level Word Frequency sorting and Correlation Coloring allows the most effective species and supplements for the disease or demand to stand out and be easily understood at a glance.
-
-
Super Species Recognition – Before Correlation Coloring
-
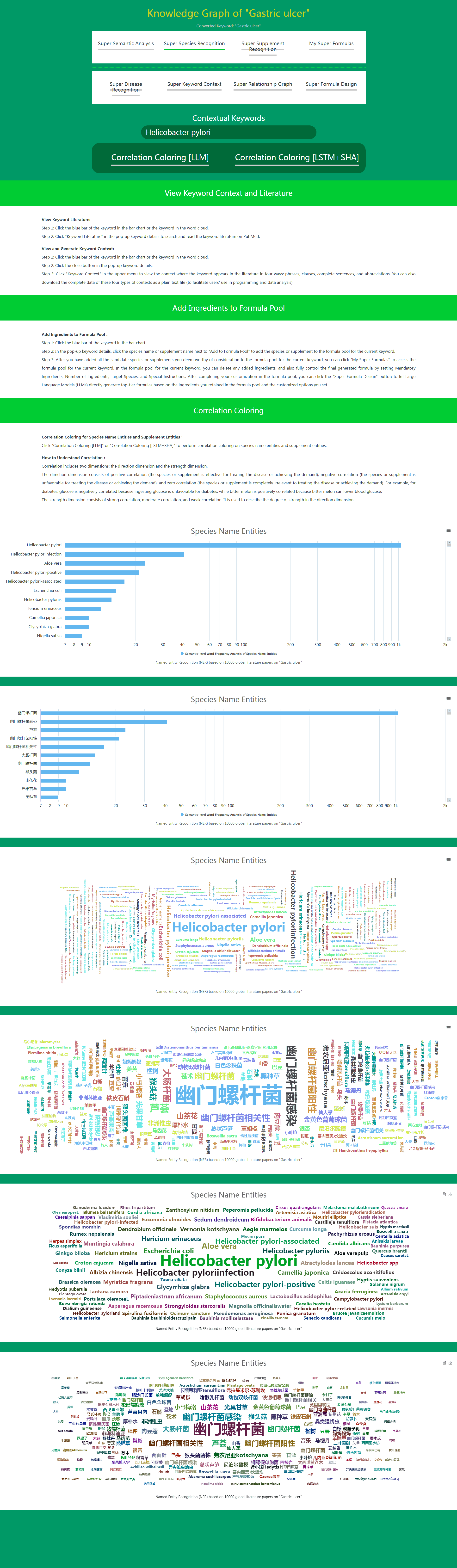
-
Super Species Recognition – After Correlation Coloring
-
-
Super Supplement Recognition – Before Correlation Coloring
-
-
Super Supplement Recognition – After Correlation Coloring
-
-
Why Are Formulas Designed Solely with Large Language Models Inadequate?
-
There are three main disadvantages of formulas designed solely with Large Language Models:
1. Hallucinations. This is unavoidable. It is determined by the characteristics of the Multi-Head Self-Attention Mechanism of the Transformer architecture underlying large language models. For example, when using Doubao solely to design a formula for gastric ulcers, you will find that the generated formula often includes an ingredient called Slippery Elm Bark Powder (Slippery Elm) and claims it is derived from the bark of Ulmus rubra. However, you cannot find any literature linking Slippery Elm or Ulmus rubra to gastric ulcers or gastric acid on PubMed.
2. Mediocrity. Formulas generated solely by large language models are very mediocre (and sometimes completely ineffective). This is because when designing formulas, large language models tend to use the most common and marginally useful (or sometimes completely useless) supplements, rather than the most effective but potentially less common ones. The answers provided by large language models are based on probability distributions. Essentially, it generates the most probable answer within a certain range. Firstly, this range is not global; secondly, the most probable answer within this range does not mean it is the correct answer for that range.
3. Randomness. The formula generated each time is different. The randomness that has to be introduced to prevent overfitting and improve generalization ability leads to inconsistent answers with each generation. This results in different formulas being generated for exactly the same requirements, leaving users at a loss.
-
Why Can Daza Matrix + Large Language Models Design Top-Tier Formulas?
-
1. Using CNN+NLP+Domain-Specific NLP to Resolve Hallucinations and Randomness
Compared with LLMs, the CNN+NLP+Domain-Specific NLP solution can better understand and process professional terminology and domain knowledge, reducing misunderstandings caused by general-purpose models. At the same time, it is more modular and interpretable, facilitating adjustments and optimizations for specific tasks and enabling tracking of the model's decision-making process, thus completely eliminating hallucinations.
Unlike the generative approach of LLMs, the CNN+NLP+Domain-Specific NLP solution relies more on rule-based and statistical models, resulting in highly stable generated outcomes.
2. Filtering Out Mediocrity Through Custom Formula Pools
For any disease or demand, Daza Matrix identifies the most effective species and supplements from over 2 million species and more than 100,000 supplements worldwide. By only adding the most effective candidate species and candidate supplements to the custom formula pool, we completely eliminate the possibility of large language models choosing mediocre options. A simple truth: if you only select from Olympic champions, you will not get underperforming athletes.
Super Member Max Privileges
-
Super Member and Super Member Max have identical features except for the differences outlined below.
-
Differences Between Super Member and Super Member Max
When using the Super Data of the Semantic-level Knowledge Graph – Daza Matrix: for each set of keywords, if the number of documents to be retrieved and analyzed is no more than 30,000, Super Member will process all of them. If the number of documents exceeds 30,000, Super Member will process 20% of them. In contrast, Super Member Max can process 100% of all documents for any set of keywords.
For example, if a keyword combination retrieves 500,000 documents, Super Member will process 100,000 documents, while Super Member Max will process all 500,000 documents.